Understanding how to effectively read Word documents in Python is crucial for a wide range of applications, such as data processing, automation, and document analysis.
With Python, anything can be done including reading and writing Word documents.
Python can read Word documents (.doc, .docx) using the python-docx library. This powerful library enables developers to extract text, formatting details, tables, and more from Word documents with ease.
By utilizing python-docx, you can gain access to the textual content, retrieve formatting information, and even modify the documents as needed.
In this article, we will explore the capabilities of python-docx and guide you through the process of reading Word documents in Python, equipping you with the necessary knowledge to work with these file formats efficiently.
The Word document file I will be using in this article as an example, can be accessed from this URL: Link to the document.
How to read Word documents in Python
When it comes to reading Word documents in Python, the python-docx library stands out as a popular and powerful tool.
This library provides extensive functionality to interact with Word documents, allowing you to extract valuable information, manipulate content, and analyze data seamlessly.
Python-docx offers a wide range of features and capabilities, making it a versatile solution for handling Word documents.
Some of the key functionalities include:
- Text Extraction: With python-docx, you can extract the textual content from paragraphs, headings, tables, and other elements present in Word documents. This enables you to retrieve and process the information contained within the documents programmatically.
- Formatting Access: The library allows you to access formatting details such as font styles, colors, paragraph alignment, and more. By accessing formatting information, you can analyze and manipulate the visual aspects of the document as per your requirements.
- Table Manipulation: Python-docx provides convenient methods to work with tables within Word documents. You can extract data from tables, modify existing tables, or create new tables dynamically.
- Document Modification: In addition to reading, python-docx enables you to make changes to Word documents. You can add or remove text, update formatting, insert images, and perform various other modifications programmatically.
To get started with python-docx, you need to install the library using the pip package manager. We’ll install the library in a virtual environment:
Installing the python-docx library within a virtual environment is not only a good practice but also offers several advantages.
A virtual environment provides an isolated and self-contained environment for your Python projects, allowing you to manage dependencies without interfering with the system-wide Python installation.
This ensures project-specific package versions and avoids conflicts between different projects.
Using a virtual environment helps maintain project consistency and portability.
To install the python-docx library within a virtual environment, follow these steps:
Step 1: Open your command-line interface (CLI) or terminal.
Step 2: Create a new virtual environment by running the following command:
python -m venv myenv
Here, myenv can be replaced with the desired name for your virtual environment.
Step 3: Activate the virtual environment:
- On Windows:
myenv\Scripts\activate
- On macOS/Linux:
source myenv/bin/activate
Once activated, your CLI prompt should reflect the virtual environment name.
Step 4: Install the python-docx library
Now, within the virtual environment, install the python-docx library by running the following command:
pip install python-docx
Pip will download and install the library along with its dependencies into the virtual environment.
How to read .docx file in Python
To read .docx files in Python, we need to import the necessary modules and initialize a Word document object.
Follow the steps below to get started:
1. Import the docx module
import docx
2. Initialize a Word document object
document = docx.Document('path_to_file.docx')
Replace 'path_to_file.docx' with the actual path to your .docx file.
Using the example document I provided you with earlier, you should place the document in the same folder as your Python script and import the document like this:
# Load the Word document
document = Document('example_word_document.docx')
This creates a document object that represents the contents of the Word document.
3. Read the .docx file
Once we have the Word document object, we can access its content and retrieve the text from the paragraphs, headings, tables, and other elements within the document.
Here’s how you can iterate over the paragraphs in the document and print them in the terminal.
To iterate over the paragraphs in the document and print them in the terminal, follow these steps.
Iterate over the paragraphs in the document
# Define the desired style name
desired_style = 'Normal'
# Extract paragraphs based on style
for paragraph in document.paragraphs:
if paragraph.style.name == desired_style:
print(paragraph.text)By using a loop, we can access each paragraph in the document and retrieve its text using the .text attribute.
Printing the text in the terminal allows us to view the content of each paragraph.
You can perform any necessary processing or analysis on the extracted text within the loop.
Output paragraphs to a .txt file
Additionally, you can output the paragraphs into a .txt file for further analysis or documentation purposes.
Here’s how you can do that:
# Write the extracted paragraphs from a .docx to a .txt file
with open('output.txt', 'w') as file:
for paragraph in document.paragraphs:
if paragraph.style.name == desired_style:
file.write(paragraph.text + '\n')
In this code snippet, we create a new file called output.txt in write mode ('w'). Then, we iterate over the paragraphs and write each paragraph’s text to the file.
The '\n' character adds a new line after each paragraph, ensuring readability in the .txt file. More on how to output Python script results to a file here.
By executing these steps, you can iterate over the paragraphs in the document, displaying their content in the terminal and saving them to a .txt file.
This allows for easy analysis, further processing, or sharing of the extracted text.
Feel free to customize the code examples based on your specific requirements and naming conventions.
Here, we looked at how you can extract paragraphs only. But, there are other elements in a Word document too.
Let’s see how you can extract other text formats from a Word document.
How to extract text from a Word document in Python (headings, list, tables)
When working with Word documents in Python, it’s crucial to know how to access the textual content of different elements such as paragraphs, headings, and tables.
By understanding these techniques, you can extract and manipulate the specific information you need.
Let’s explore how to access the text content from these elements within a Word document.
To extract text from paragraphs
Each paragraph in a Word document can be accessed using the paragraphs attribute of the document object.
You can iterate over the paragraphs using a loop and retrieve the text using the .text attribute.
For example:
for paragraph in document.paragraphs:
text = paragraph.text
# Process the text as needed
To extract text from headings
Headings within a Word document are represented as paragraph objects with specific styles.
To extract text from headings, you can check the paragraph’s style and filter based on the desired heading levels.
For instance:
for paragraph in document.paragraphs:
if paragraph.style.name.startswith('Heading'):
text = paragraph.text
print(text)
# Process the heading text as needed
To extract text from tables
Tables in Word documents can be accessed through the tables attribute of the document object.
You can iterate over the tables and further iterate over the rows and cells to extract the desired text.
Here’s an example:
for table in document.tables:
for row in table.rows:
for cell in row.cells:
text = cell.text
# Process the table cell text as needed
To access a specific table from a Word document when you have multiple tables, you can utilize indexing or specific identifiers to target the desired table.
Here’s how you can achieve that:
a) Accessing a table by index
If you know the index of the table you want to access, you can use it to retrieve the table object.
Keep in mind that table indexing starts from 0 (following the rules of Python indexing).
Here’s an example:
table = document.tables[0] # Accesses the first table in the document
for row in table.rows:
for cell in row.cells:
text = cell.text
print(text)
# Process the table cell text as neededIn this code snippet, document.tables[0] retrieves the first table from the tables attribute of the document object.
You can replace 0 with the index of the desired table.
Just make sure you don’t go out of index range.
Otherwise, use an exception handling block to mitigate scenarios where you do not know the number of tables in a Word document.
b) Accessing a table based on a specific identifier
If your tables have unique identifiers, such as a table caption or specific content, you can use that information to identify and access the table.
To access the “Milestones” table from a Word document based on specific content such as the word “milestone,” you can iterate over the tables in the document and search for the target content within each table.
Here’s an example code that demonstrates this approach:
target_content = "milestone" # Content to identify the table
for table in document.tables:
for row in table.rows:
for cell in row.cells:
if target_content in cell.text.lower():
# Found the desired table based on the target content
print(cell.text)
# Perform operations on the table
break
if target_content in cell.text.lower():
break
if target_content in cell.text.lower():
breakIn this code, we iterate over the tables, rows, and cells in the document, checking if the target_content is present within any cell’s text.
By converting the cell’s text to lowercase (cell.text.lower()) and comparing it with the lowercase version of the target_content, we make the search case-insensitive.
Once we find the cell containing the target_content, we assume that the associated table is the “Milestones” table.
You can perform operations on this table or customize the code based on your specific requirements.
By utilizing this approach, you can extract the “Milestones” table from a Word document based on the presence of specific content, such as the word “milestone” within the table’s cells.
By using either the index or a specific identifier, you can access the desired table from a Word document that contains multiple tables.
Choose the approach that suits your needs based on the available information about the tables.
How to extract extra information such as font styles, colors, and paragraph alignment from Word documents
When working with Word documents in Python, it’s often necessary to extract additional information beyond the plain text content.
Formatting details such as font styles, colors, and paragraph alignment can provide valuable insights into the document’s visual presentation.
To access font styles, colors, and paragraph alignment, we’ll leverage the capabilities of the python-docx library.
This library provides a rich set of features to extract and manipulate various aspects of Word documents.
Let’s now explore some code snippets that demonstrate how to extract font styles, colors, and paragraph alignment from Word documents.
paragraphs = []
for paragraph in document.paragraphs:
paragraphs.append(paragraph)
last_paragraph = paragraphs[-1]
for run in last_paragraph.runs:
font_name = run.font.name
font_size = run.font.size
print(font_name, font_size)
# Access other font attributes as needed
In this code snippet, we iterate over paragraphs, extract the last paragraph of the document, and iterate through the runs in the paragraph.
For each run, we retrieve the font name (run.font.name) and font size (run.font.size).
You can access additional font attributes, such as bold, italic, underline, and color, by referring to the appropriate properties of the run.font object.
After executing the code, you should get the results that look like this:
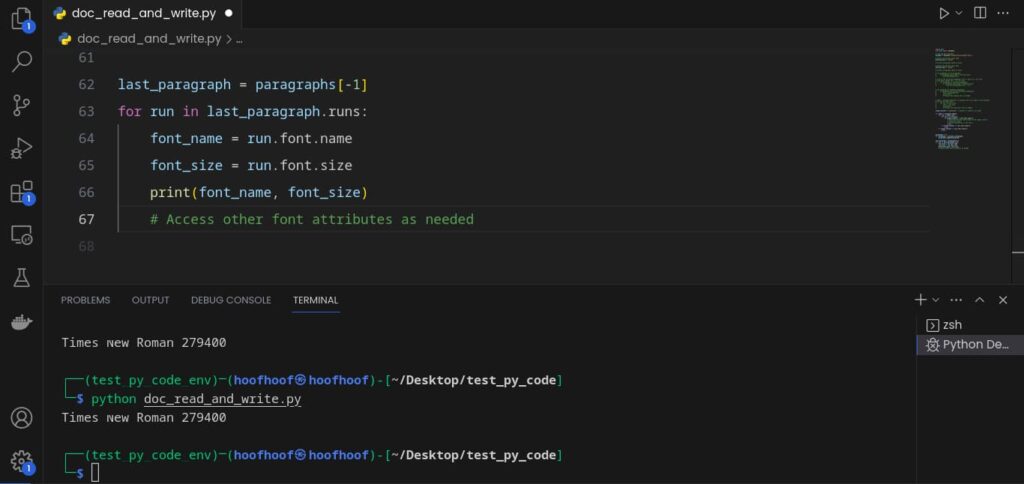
When extracting formatting details from Word documents using the
python-docxlibrary, it’s important to note that if a paragraph has an inherited style, accessing certain attributes may returnNone.Inherited styles are styles applied to a higher-level element, such as a document or section, and are inherited by paragraphs within that element.
To handle inherited styles, it is recommended to traverse the document hierarchy and check for any parent elements that may affect the formatting of the target paragraph.
Otherwise, ensure that each element in your document has its own explicitly defined styles. This involves highlighting the text and defining specific styles for the element, such as the font, font size, alignment, and other formatting attributes.
By explicitly setting styles for individual elements, you can ensure consistent and accurate extraction of formatting details when working with Word documents in Python.
This approach avoids any potential confusion caused by inherited styles and allows for precise control over the appearance of your document’s content.
You can also retrieve font colors like this:
for paragraph in document.paragraphs:
for run in paragraph.runs:
font_color = run.font.color.rgb
print(font_color)
# Access other color attributes as neededIn this code, we access the color attribute of the font (
run.font.color.rgb).The color is represented in RGB format, allowing you to extract the red, green, and blue components individually.
Besides, obtain paragraph alignment
Here’s how:
alignment = last_paragraph.alignment
print(alignment)
That’s how you extract formatting details such as font styles, colors, and paragraph alignment from Word documents.
Handling exceptional cases when handling Word documents with Python
Working with Word documents in Python can sometimes present challenges or errors that require careful handling.
It’s important to be aware of these potential issues and have strategies in place to overcome them.
When handling Word documents in Python, it’s crucial to be prepared for possible exceptions or errors that can occur during document processing.
Here are some common troubleshooting tips and solutions to help you overcome these challenges:
- Handling File Not Found Errors: If you encounter a “FileNotFoundError” when attempting to open a Word document, double-check the file path to ensure it is correct. Verifying the file’s existence and the path’s accuracy can help resolve this issue.
- Dealing with Unsupported Document Formats: Certain Word document formats, such as older .doc files (e.g. .doc files from Word 2003 and earlier), may not be fully supported by the
python-docxlibrary. If you encounter errors when working with these formats, consider converting them to the newer .docx format before processing. - Handling Invalid or Corrupted Documents: If you come across an invalid or corrupted Word document, it can lead to errors during processing. To mitigate this, consider implementing error-handling mechanisms to gracefully handle such cases and provide meaningful feedback to the user.
Best Practices for Error Handling and Graceful Program Termination
To ensure smooth and robust handling of exceptions when working with Word documents in Python, it’s essential to follow best practices for error handling and graceful program termination.
Consider the following tips:
- Use try-except Blocks: Wrap your code that interacts with Word documents in try-except blocks to catch and handle specific exceptions. This allows you to control the flow of your program and provide custom error messages or alternative actions.
- Logging and Debugging: Implement logging and debugging techniques to capture relevant information about exceptions or errors. This helps in troubleshooting and understanding the root cause of issues during document processing.
- Graceful Termination: In cases where an exception occurs that cannot be handled, ensure your program terminates gracefully. Clean up any resources or temporary files, and provide appropriate feedback to the user to indicate that an error has occurred.
FAQ
How to read a Word document table in Python?
To read a Word document table in Python, you can utilize the python-docx library.
Follow these steps to read a table from a Word document:
Step 1: Import the necessary docx module
from docx import Document
Step 2: Load the Word document with the table using the Document class
doc = Document('path/to/document.docx')
Replace 'path/to/document.docx' with the actual path to your Word document.
Step 3: Iterate over the tables in the document
for table in doc.tables:
# Process each table
for row in table.rows:
# Process each row
for cell in row.cells:
# Extract cell content
cell_text = cell.text
# Do something with the cell text
This code snippet iterates over each table in the document, then each row within the table, and finally, each cell within the row.
You can access the text content of each cell using the cell.text attribute and perform further processing or analysis as needed.
Customize the code based on your specific requirements, such as storing the table data in a structured format or performing calculations using the cell values.
How to extract and load text from .docx files in Python using pandas
To read a .docx file in Python using pandas, you can follow these steps:
Step #1: Install pandas and python-docx libraries
First, you need to install the required libraries. Install the python-docx and pandas libraries using the following command:
pip install python-docx pandas
Step #2: Import the necessary pandas and docx modules
from docx import Document
import pandas as pd
Step #3: Load the Microsoft Word document
Load the .docx file using the Document class from the python-docx library:
doc = Document('path/to/file.docx')
Replace 'path/to/file.docx' with the actual path to your .docx file.
Step #4: Extract the text content from the paragraphs in the document
paragraphs = []
for paragraph in doc.paragraphs:
paragraphs.append(paragraph.text)
Step #5: Create a pandas DataFrame from the extracted paragraphs
df = pd.DataFrame(paragraphs, columns=['Paragraph'])
This step converts the list of paragraphs into a DataFrame with a column named ‘Paragraph’.
Step #6: Work with your dataframe
Now you can work with the DataFrame as needed.
For example, you can display the first few rows of the DataFrame:
print(df.head())
This will print the first few paragraphs in the DataFrame.
Here’s the complete code example:
from docx import Document
import pandas as pd
# Load the .docx file
doc = Document('path/to/file.docx')
# Extract text content from paragraphs
paragraphs = []
for paragraph in doc.paragraphs:
paragraphs.append(paragraph.text)
# Create a DataFrame
df = pd.DataFrame(paragraphs, columns=['Paragraph'])
# Display the first few rows
print(df.head())
Remember to replace 'path/to/file.docx' with the actual path to your .docx file.
What are the supported file formats for reading in Python using python-docx?
The python-docx library in Python supports reading and manipulating Word documents in the .docx and .doc formats, encompassing Word documents from 2007 onwards. However, it does not support the older .doc format used by Word 2003 and earlier versions. Other than that, python-docx provides comprehensive functionality for working with Word documents.
Conclusion
In conclusion, Python and the python-docx library provide a robust and efficient solution for working with Word documents.
Whether it’s extracting content, modifying formatting, or automating document-related tasks, Python’s flexibility and the extensive capabilities of the python-docx library empower developers to handle Word documents effectively.
I encourage you to further explore Python and its ecosystem to expand your document processing skills and discover even more possibilities for efficient and customized solutions.
Create, inspire, repeat!
![What does [::-1] mean in Python? (How to reverse a sequence)](https://crackondev.com/wp-content/uploads/2023/07/Reversing-sequences-in-Python-using-slice-notation-and-negative-indexing.jpg)